An application that automatically downloads embedded and linked files on websites for you. #Offline browser #Website downloader #Download website #Download #Downloader #Rip
WebRipper is a small and powerful application that can download automatically large amounts of content found on any selected website.
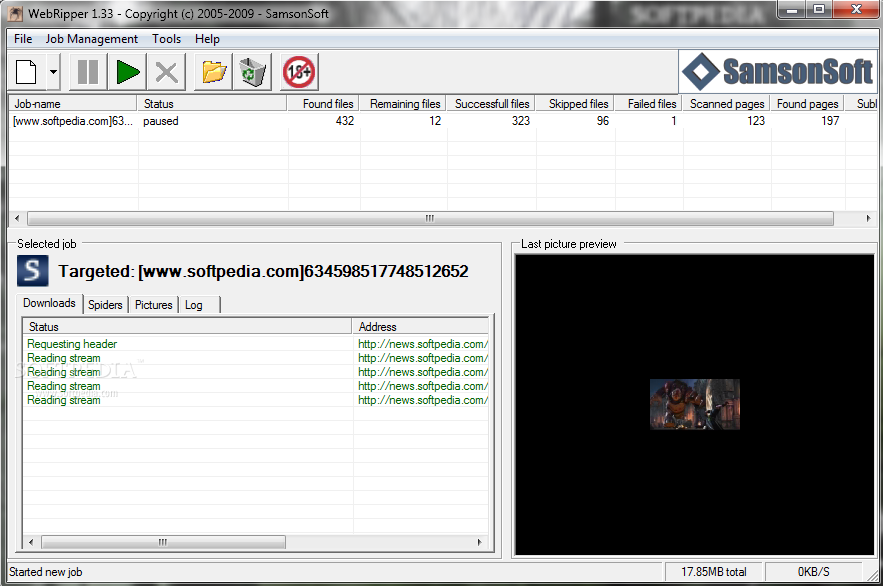
The interface of the program is standard and easy to navigate through. From the toolbar you can create a new targeted rip job or image search, pause all tasks and open the download folder.
When you enter the "New Job" wizard, you have to type in the URL(s) and select at least one filter - images, video, sound, document, others. Just as well, you can select the file formats for each of the aforementioned categories.
Optionally, you can input a username and password if this is required by the specified website. Also, you can configure scan and download restrictions (unrestricted, follow links within domain only, don't go higher than the specified directory), and adjust the number of sub-levels to be inspected.
You can use a filter to include or exclude certain keywords and configure file and image restrictions (according to size, width and height).
In the queue list, you can view the current status of the job and sub-level, found, remaining, successful, skipped and failed files, as well as scanned and found pages. When you select a job, you can view a log file, the currently downloaded items and you can also preview pictures.
From the 'Preferences' area you can set the downloaded items directory, enable to autosave jobs on exit and to use server folder-structure for downloaded files, set a user agent, adjust maximum download threads per job and download buffer size, enable to scan all pages before downloading content, connect via proxy, and more.
The program uses a low amount of system resources, pops up errors only when you insert a wrong link and then try to remove it. With a good feature pack and not too difficult to use, WebRipper can certainly be one of the smart choices from its category.
Download Hubs
Webripper is part of these download collections: Offline Browsers
What's new in Webripper 1.33:
- This is a release for the Webripper 1.x series, fixing a serious bug that prevented the application from starting after some recent DNS-changes.
Webripper 1.33
add to watchlist add to download basket send us an update REPORT- runs on:
- Windows All
- file size:
- 1.1 MB
- filename:
- WebRipper_1.33.exe
- main category:
- Internet
- developer:
- visit homepage
Microsoft Teams

Windows Sandbox Launcher

ShareX

calibre

4k Video Downloader

Zoom Client

7-Zip

IrfanView

Context Menu Manager

Bitdefender Antivirus Free

- IrfanView
- Context Menu Manager
- Bitdefender Antivirus Free
- Microsoft Teams
- Windows Sandbox Launcher
- ShareX
- calibre
- 4k Video Downloader
- Zoom Client
- 7-Zip