A reliable application that eliminates the overhead of SQL query processing, enabling applications with predictable access patterns to run faster. #Database engine #SQL storage #Database configuration #Storage #SQL #Database
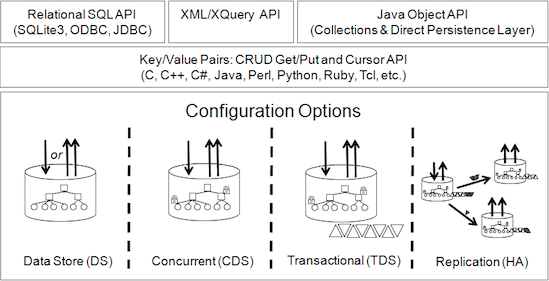
Berkeley DB is a practical database engine that provides developers with fast, reliable, local persistence with zero administration. The database comprises of key-value libraries that are fine-tuned to deliver high-performance data management services to the applications you are developing.
A noteworthy function of the suite it can facilitate the development of custom data management solutions using well-proven technologies. The package can be configured to address all sorts of needs of the applications, regardless of whether they are for mobile, desktop or data centers.
The idea behind the database is to provide you with multiple versatile building options, so the possibilities are limitless. Developers can analyze the available builds and compile the one library that is most appropriate for the app’s configuration. In fact, this is a reliable solution that backed up by 17 years of experience for a wide array of solutions, from mobile apps to e-commerce.
Then again, you should bear in mind that the data management solution is designed for enterprise-class databases. Consequentially, you should expect non-blocking writes, high scalability, in-memory caching, advanced recovery features, replication, configurable packages, low-latency reads, ACID transactions and high throughput from it.
All things considered, Berkeley DB is a versatile, fast and scalable data management service that can provide you with utmost features for your application, while still being transparent to your end-users.
System requirements
Berkeley DB 18.1.32
add to watchlist add to download basket send us an update REPORT- runs on:
- Windows All
- file size:
- 36.9 MB
- filename:
- db-18.1.32_64.msi
- main category:
- Internet
- developer:
- visit homepage
IrfanView

Microsoft Teams

4k Video Downloader

Bitdefender Antivirus Free

Windows Sandbox Launcher

calibre

paint.net

7-Zip

Zoom Client

ShareX

- 7-Zip
- Zoom Client
- ShareX
- IrfanView
- Microsoft Teams
- 4k Video Downloader
- Bitdefender Antivirus Free
- Windows Sandbox Launcher
- calibre
- paint.net