An Optical Character Recognition (OCR) engine started at HP Labs and now under development at Googlethat can help users grab texts from pictures. #OCR engine #Image to text #Read image #OCR #Text #Recognition
Transforming text into graphics is not too difficult a task, but trying to extract words from an image file might be quite troublesome. This kind of job needs a special type of equipment, more precisely an Optical Character Recognition (OCR) capable utility.
One of the top engines that were created for these purposes is Tesseract and those who intend to try and use it have at their disposal the Tesseract-OCR package.
Before getting to use this tool, it is a good idea to pay attention to the setup procedure as it may provide some useful extras that may be required when handling documents in many foreign languages.
More precisely, the 'Language data' section enables you to choose the desired languages and also add the math and equation detection module if you plan to extract this type of data as well.
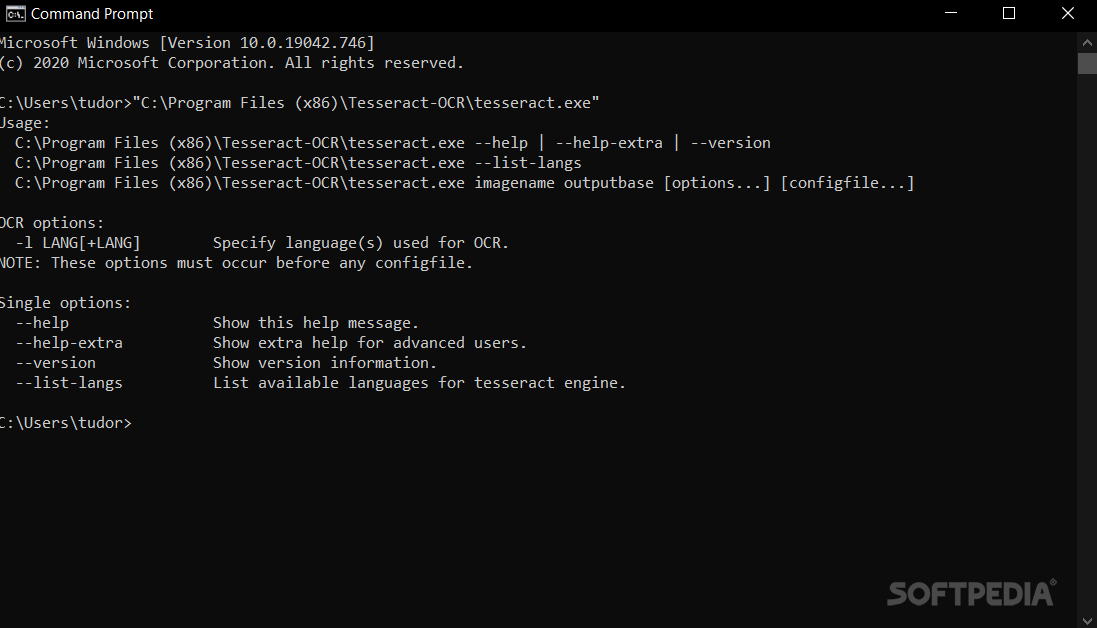
As soon as Tesseract-OCR is installed onto your system, you will be able to deploy it via command-line and start using it immediately. There are only a few parameters to apply when working on the target files and they are explained well enough.
The most important values are those for the 'pagesegmode' parameter and they pertain mainly to the page segmentation and image handling.
One of the main strong points of Tesseract-OCR is its ability to recognize and process a variety of graphical image file types. Another great thing about this utility is its processing speed which should satisfy the needs of any user.
When it comes to saving the extracted content, the program generates text (TXT) files with the names you set before starting the task.
All things considered, this command-line application should be not to difficult to understand for less experienced users as it uses a quite simplified syntax. It is quick in processing and accurate enough to be considered among the best in its category.
What's new in Tesseract-OCR 5.3.3.20231005:
- Revert "Use HTTP for model download"
- Use gnu_printf for Windows build
- Test new installer cross build with pacman and msys
- Update Ubuntu runner for GitHub action
Tesseract-OCR 5.3.3.20231005
add to watchlist add to download basket send us an update REPORT- PRICE: Free
- runs on:
-
Windows 11
Windows 10 32/64 bit
Windows 8 32/64 bit
Windows 7 32/64 bit
Windows Vista 32/64 bit
Windows XP 32/64 bit - file size:
- 47.8 MB
- filename:
- tesseract-ocr-w64-setup-5.3.3.20231005.exe
- main category:
- Programming
- developer:
- visit homepage
calibre

Zoom Client

ShareX

IrfanView

Windows Sandbox Launcher

4k Video Downloader

7-Zip

Bitdefender Antivirus Free

Microsoft Teams

paint.net

- Bitdefender Antivirus Free
- Microsoft Teams
- paint.net
- calibre
- Zoom Client
- ShareX
- IrfanView
- Windows Sandbox Launcher
- 4k Video Downloader
- 7-Zip