14 DAY TRIAL //
14 DAY TRIAL // A web crawler is an application that allows you to download a web page or even an entire website so you can navigate through it once the program has finished its job. This kind of software is also known as web spiders or offline browsers. You may ask yourself, what's the point of this type of programs? Well, it could come in handy when your Internet connection barely stays alive and it takes forever to load a single page. At that point, you can run the web crawler application, let it run for a couple of minutes/hours and when you return, you will be able to browse through your favorite website faster than browsing on a broadband connection. Unfortunately, web crawlers are often used to steal web content or perform other illegal actions. If you decide to use a web crawler for malicious reasons, it will be your responsibility and you'll even risk court actions being taken against you.
KrawlSite is one of the few web crawlers for Linux which allows you to crawl a given website up to any link depth. It's part of the KDE project and can be run either as a unique application or can be embedded into Konqueror or any KPart-aware application.
To install KrawlSite, you'll have to download the source package and follow the generic installation instructions. You'll simply have to uncompress the archive, cd to the newly created directory and type ./configure ; make ; make install. However, in order to successfully install KrawlSite, your system has to meet all its requirements. It shouldn't cause any problems on a system with KDE environment correctly installed. Once compiling and installing was completed successfully, KrawlSite can be run by opening a terminal and executing the krawlsite command.
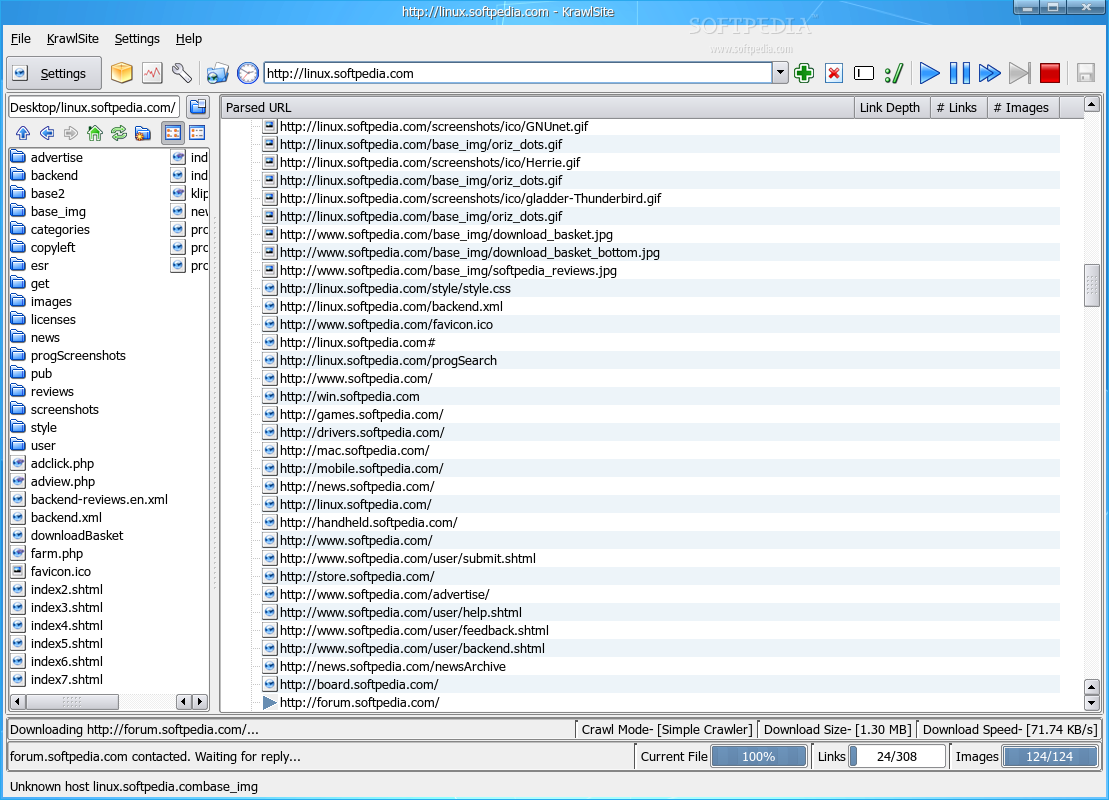
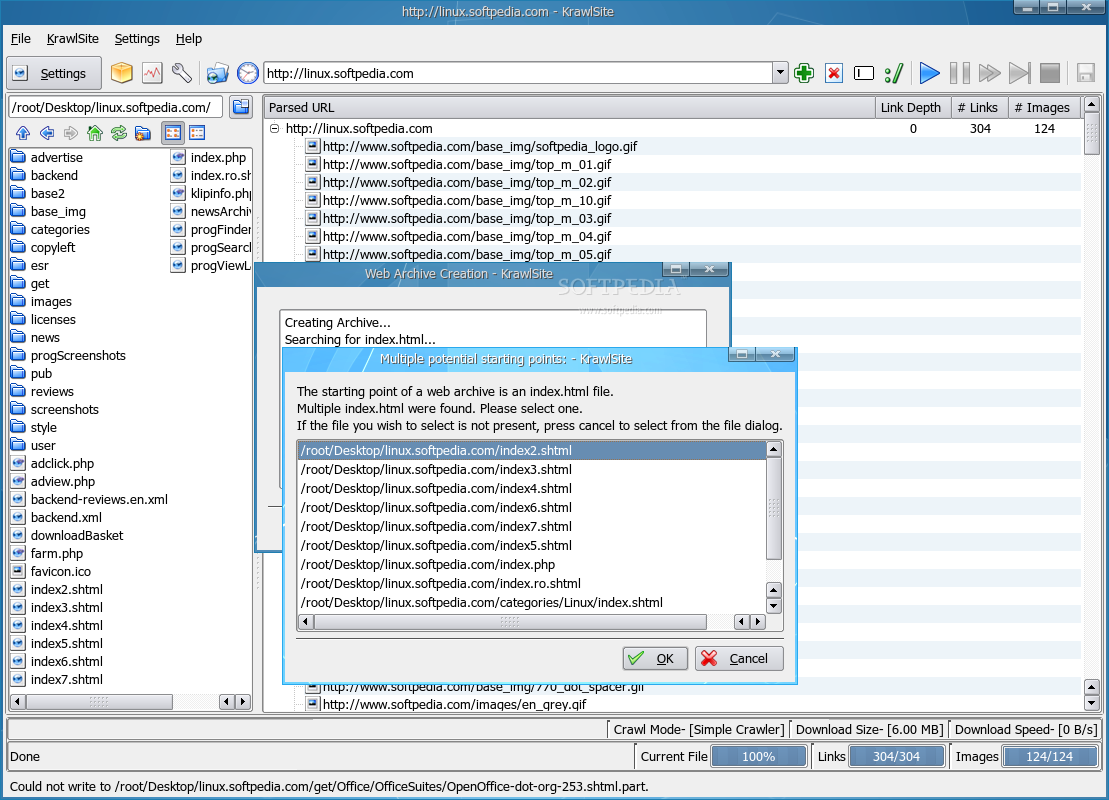
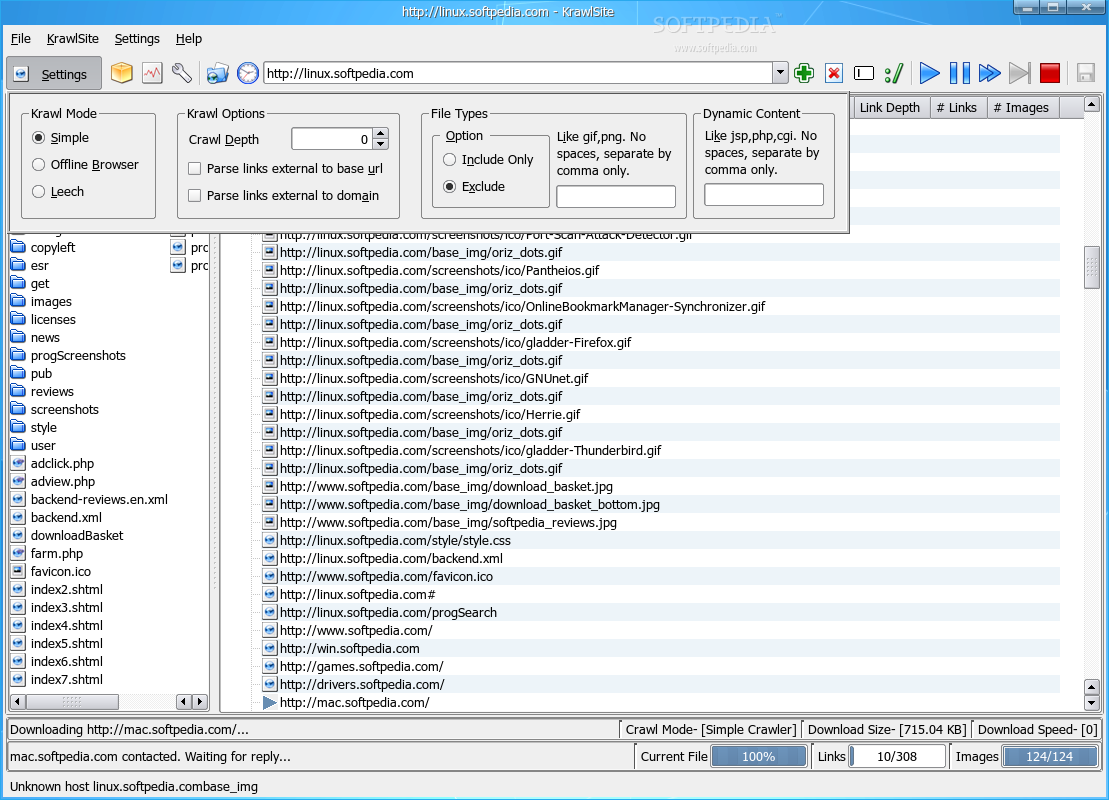
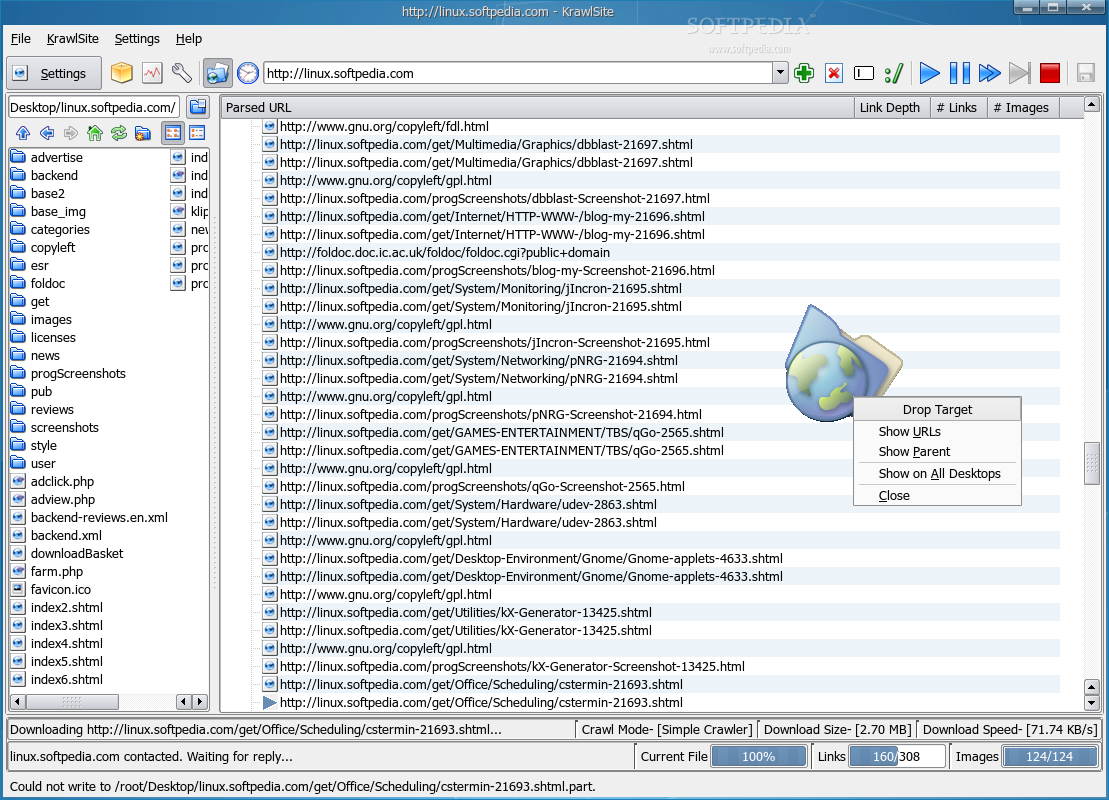
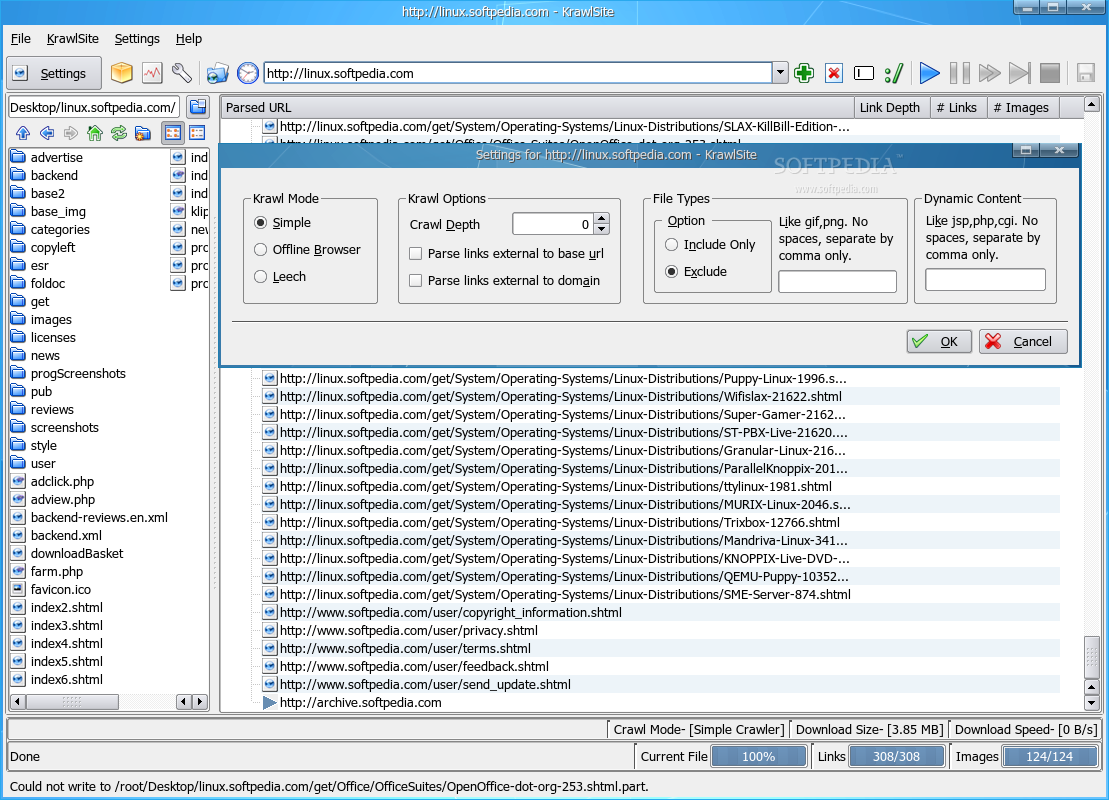
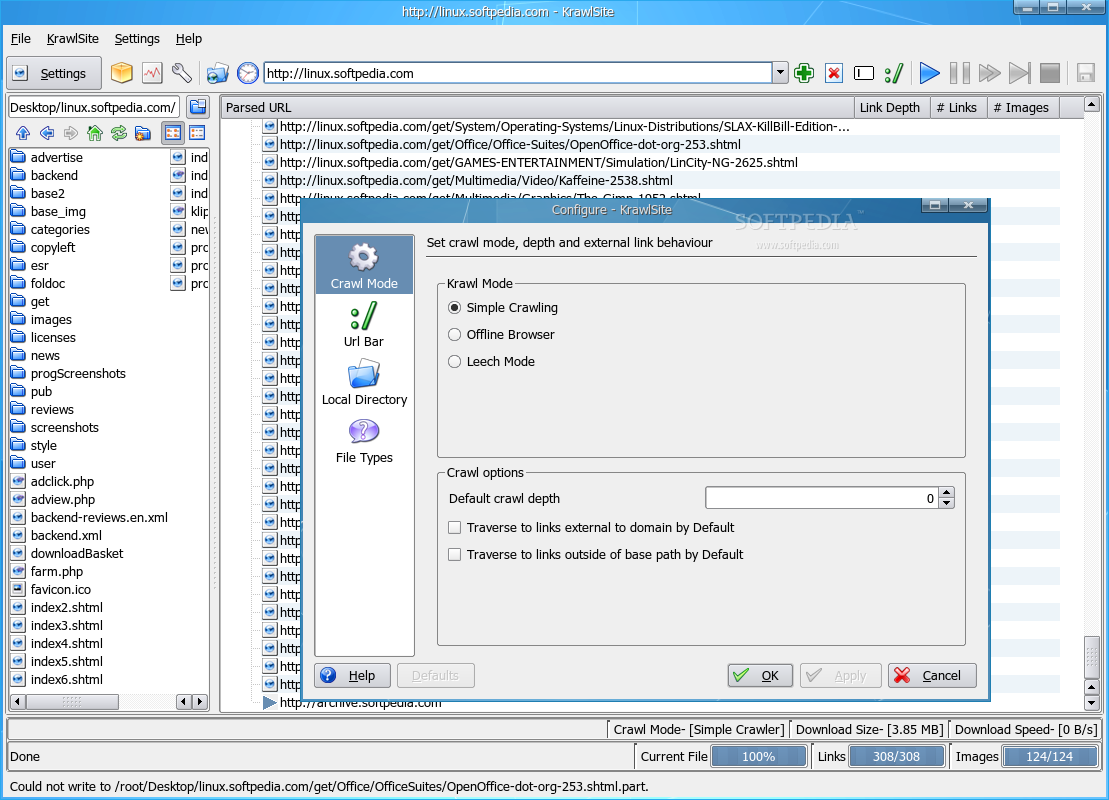
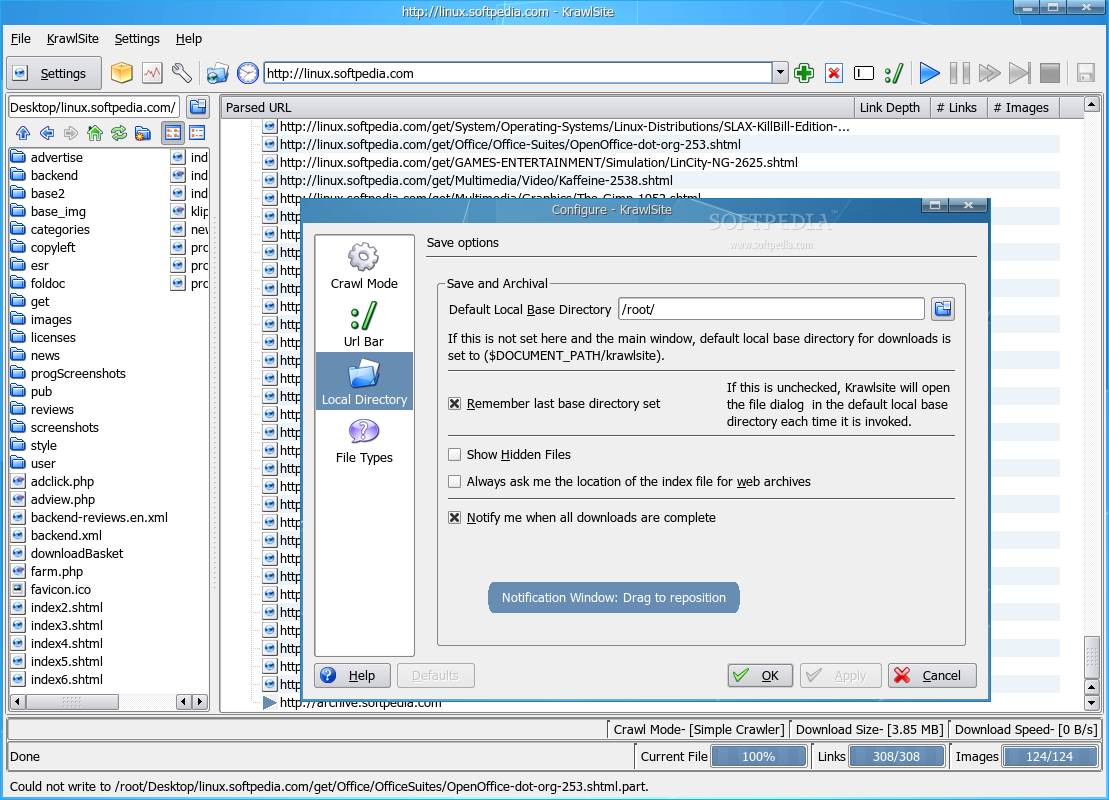
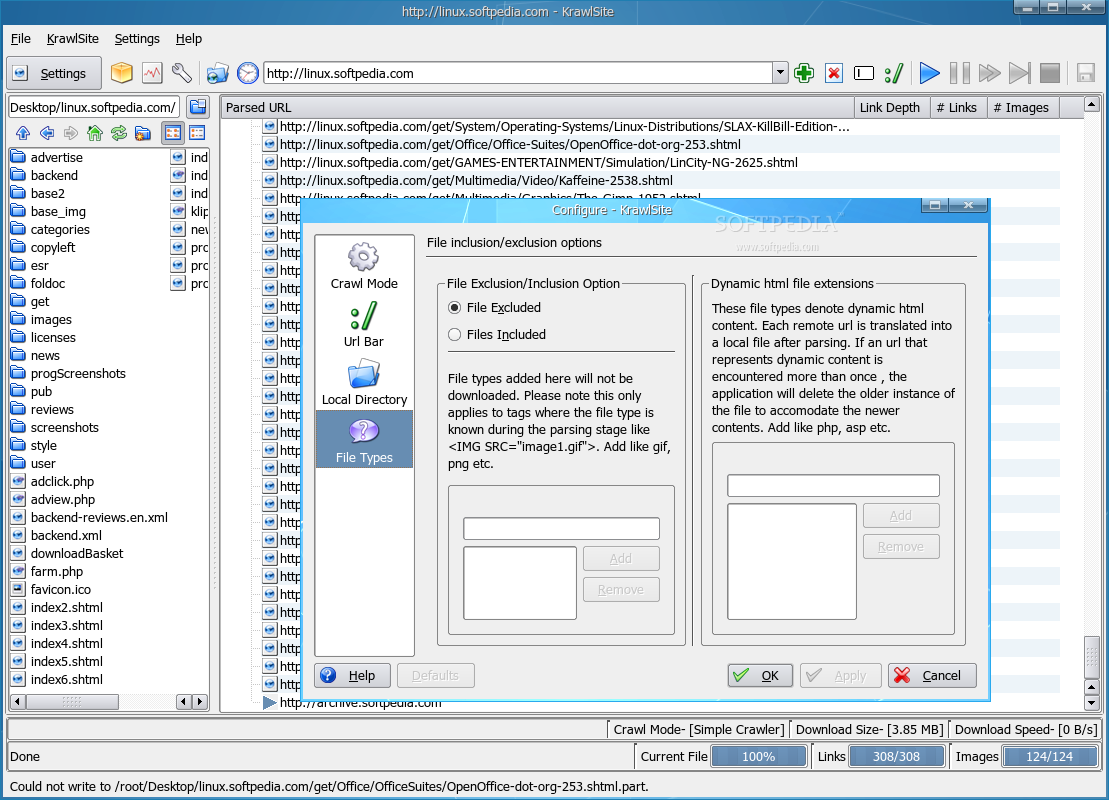
You'll notice that KrawlSite has a simple design, being also straight to the point in functionality. The main window is divided into four sections: the toolbar section in the upper part and the status bar in the lower part. The most important aspect of the application will be in the middle. This section is divided in two smaller ones: on the left you'll notice a basic local browser, while the remaining right part will consists of links discovered in the currently selected website. The local browser allows you to easily switch to an existing directory or create a new one; either way, the selected directory will be used as a download location for the files discovered on the crawled website. The toolbar contains buttons for easy access to KrawlSite's main functions. The Settings button will open a small window, which will enable you to rapidly switch some of its options. Next, you'll see the Archive button which will create a web archive file (.war) containing one of the discovered html files. Also, you'll find the Log button which will open a window containing KrawlSite's last actions and messages and the Configure button which will open the main configuration window. Next, there's the Drop target button which will open a new drop target icon, the History button which will show the last crawled websites and the address bar. Finally, the last buttons allow you to control the crawling itself. These buttons will enable you to add or delete URLs, personalize the crawl and of course, start, pause and stop the crawl. The status bar shows the crawl mode, the download size and the current download speed. Moreover, you'll notice three progress bars in the statusbar: one which shows the progress for the current file, one for the discovered links and one for the discovered images. All three of them help you develop an idea about how much time the crawl will take. The Configure window contains four sections. The first, Crawl Mode, allows you to select the crawl mode. It can either be Simple, which will save the files as downloaded, Offline Browser, which will modify links to point to files in local storage or Leech Mode which unfortunately, isn't yet implemented. From the same Crawl Mode section, you can set the crawl depth. This option will select how many links KrawlSite will follow, downloading all found content. The next section, Url Bar allows you to configure the url location bar settings, such as whether to save the location url and how many urls to save. The Local Directory section enables you to select the default base directory used for saving discovered files. The last section, File Types acts as a filter and allows you to choose which file type to be ignored and which to be included in the parsing stage. Also from this section, you can select the dynamic html file extensions. These file types denote dynamic html content and each remote url will be translated into a local file after parsing. If an url that contains dynamic content is encountered more than once, the older instance will be deleted, accommodating the newer content.
The Good
KrawlSite is a simple and easy to use web crawler/spider/offline browser. It offers most of the features needed for website crawling and can be used by anyone, regardless of their knowledge level, thanks to the simple interface design, based on functionality. There's also a tray icon which offers easy access to the application's functions.
The Bad
It wouldn't hurt if KrawlSite offered more control over the crawl process through a more advanced filter, for example. Also, KrawlSite's HandBook (Documentation) hasn't been revised since 2001 and doesn't help almost at all.
The Truth
Even if it still misses a few things, KrawlSite still is a good web crawler and you should give it a try when you'll need one.
Check out some screenshots below: