Select websites for crawling processes by specifying depth and maximum number of domains, with results being delivered in real time #Validate domains #HTTP crawler #Crawl web #Test #Check #Crawler
Website administrators have the difficult task of keeping them under surveillance all the time, starting with physical issues and ending with scripting and navigation. An important task is making sure it's easy to reach and index by search engines and with specialized applications such as Java Web Crawler this can be done in a jiffy.
You don't have to go through an installation process because the application is portable, which also means you can store it on a USB Flash drive to use on other computers as well. The only thing you need to worry about is whether or not Java Runtime Environment is deployed, because it's one of the few requirements.
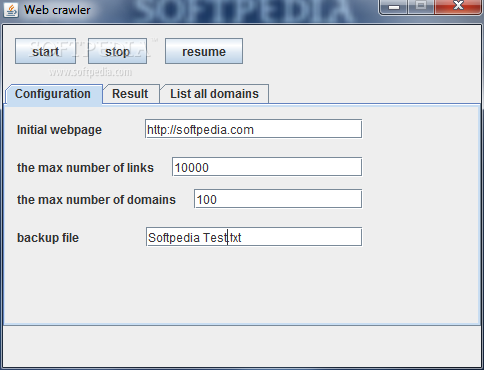
Running it brings up a compact window fitted with a few tabs for easy navigation and not to overwhelm you with too many details. The initial configuration screen is where you specify all criteria by which crawling is performed, while the results and list all domains tabs provide feedback and let you analyze gathered data.
Effort on your behalf primarily consists of writing down the URL you wish to scrape, a value for the maximum number of links to go through, which represents depth, the upper limit for domains, as well as a custom name for a file to back up data to. Needless to say that hitting the “Start” button initiates the process.
Speed at which the operation is performed mostly depends on your Internet connection and depth to dig through. As soon as you start, you might want to switch to the result tab, with a table being updated in real time with gathered data, as well as two progress sliders that let you know how far domains and links are searched.
Overall, the application is pretty easy to use by anyone because of the few requirements, with the process being done fast. However, the backup file is not always saved and data stored inside is poorly displayed. Accessing the list of domains and manually copying results is a better alternative, although not too comfortable.
Taking everything into consideration, we can say that Java Web Crawler mostly focuses on simplicity and speed. Sure, these two qualities are achieved, with data gathered and displayed in real time but little flexibility is provided when it comes to saving info of interest. It mostly comes in handy for spontaneous website crawling, because of the few configurations to handle and poor feedback and saving methods.
- runs on:
- Windows All
- file size:
- 30 KB
- filename:
- webcrawler.jar
- main category:
- Internet
- developer:
- visit homepage
Windows Sandbox Launcher

calibre

4k Video Downloader

IrfanView

Context Menu Manager

ShareX

Bitdefender Antivirus Free

7-Zip

Microsoft Teams

Zoom Client

- 7-Zip
- Microsoft Teams
- Zoom Client
- Windows Sandbox Launcher
- calibre
- 4k Video Downloader
- IrfanView
- Context Menu Manager
- ShareX
- Bitdefender Antivirus Free